OCR 图像识别
OCR 图像识别让图片、扫描件、票据、证照、截图和含图片的文档也能进入企业网盘的检索与知识处理流程。巴别鸟的 OCR 能力分布在搜索、智巢 AI、图片预览和私有化部署模块中,既可用于“搜到图片里的文字”,也可用于把识别结果复制、整理或导出为 Word 文档。
OCR 搜索
巴别鸟支持基于 OCR 结果的搜索,搜索命中的内容可以包含图片中文字、扫描文档中文字和部分文档内嵌图片的文字。用户在搜索框输入关键词时,系统可把文件名、标签、说明、全文索引和 OCR 识别结果一起参与匹配。
| 搜索对象 | 能力说明 | 部署说明 |
|---|---|---|
| 图片文件 | 支持搜索图片中的文字,适合截图、海报、证照、照片和扫描图 | 公有云和私有云能力以实际版本为准 |
| PDF 图片文档 | 支持搜索由扫描图片组成的 PDF 中的文字 | 目前主要在私有云平台作为可选能力 |
| Office 文档内图片 | 支持搜索 Word、Excel、PPT 文档中图片里的文字 | 目前主要在私有云平台作为可选能力 |
| 多语种内容 | 支持多语种和多语种混排识别 | 识别效果受图片质量、语言模型和部署配置影响 |
OCR 搜索仍遵循巴别鸟权限体系。用户只能搜索和打开自己有权限访问的文件,OCR 不会绕过部门、项目、分享、文件访问控制或加密文件夹边界。
智巢 AI 中的 OCR
智巢 AI 模块可对图片进行 OCR,提取图片中的文字内容。对于发票、护照、证照等具有固定结构的文件,系统可按场景输出更接近原始排版或字段结构的结果,便于后续整理、复制、问答和归档。

常见使用方式包括:
- 上传或选择图片后执行 OCR,提取图片中的文字。
- 对发票、护照、证书、票据等特殊文件输出结构化或排版后的结果。
- 将 OCR 结果导出为 Word 文档,便于进一步编辑、审批或归档。
- 与 AI 助理、文档助手、知识库机器人结合,对识别结果继续问答、摘要或生成说明。
图片预览中的 OCR
在图片预览器中,用户可以直接选择 OCR 操作,对当前图片进行文字识别。识别结果可在侧边区域展示,并支持复制或导出为 Word 文档。这适合用户在浏览图片、扫描件、手写记录或外部资料时快速提取文字。
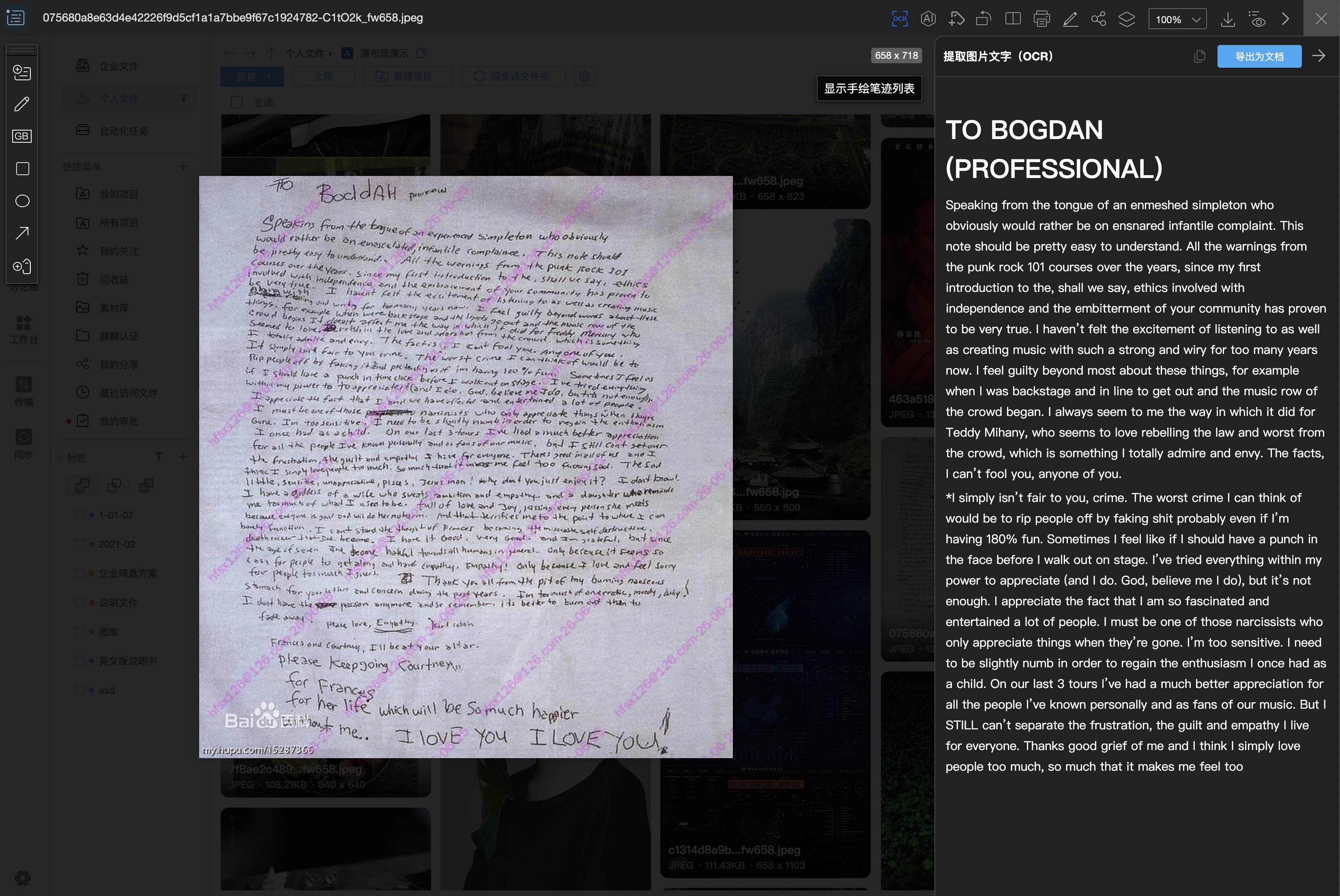
图片预览 OCR 的典型场景包括:
- 从截图、海报、合同扫描件中提取文字。
- 识别中英文混排、多语种混排内容。
- 识别手写字,辅助整理会议记录、签批意见或纸质资料。
- 将识别结果导出为 Word,交给后续编辑、审批或知识库加工流程。
私有化部署方式
私有部署时,OCR 可按企业的数据安全、性能和预算要求选择不同技术路线:
| 方式 | 说明 | 适用场景 |
|---|---|---|
| 传统 OCR | 以 CPU 处理为主,适合常规图片文字识别和批量索引 | 对 GPU 要求较低、以通用 OCR 为主的环境 |
| AI OCR | 依托智巢 AI 和模型能力,适合复杂版式、证照、票据、多语种和手写内容 | 需要购买或部署智巢 AI,对识别质量和结构化输出要求更高的环境 |
在私有化项目中,OCR 是否开启、索引范围、支持格式、处理并发、模型部署和 GPU/CPU 资源应在实施阶段确认。对涉密或高合规资料,建议明确 OCR 数据流向、缓存策略、日志留存和权限继承规则。
使用建议
- 对图片、扫描件和票据较多的企业,建议把 OCR 与高级搜索、标签、素材库、瀑布流和 AI 搜图一起启用。
- 对合同、证照、个人信息和敏感资料,建议同时启用权限、水印、敏感内容识别和审计日志。
- 对需要长期检索的扫描 PDF,可在私有化部署中评估批量 OCR 索引和后台处理资源。
- 对发票、护照、证书等结构化资料,可优先使用智巢 AI OCR,再按业务要求导出为 Word 或进入知识库。